
”Ea este frumoasă. El este deștept. El citește. Ea spală vase. El construiește. Ea coase. El predă. Ea gătește. El face cercetare. Ea crește un copil. El cântă la un instrument. Ea este îngrijitoare. El este politician. El face mulți bani. Ea face un tort. El este profesor. Ea este asistentă.” – așa arată o traducere făcută de Google Translate din limba maghiară în limba engleză.
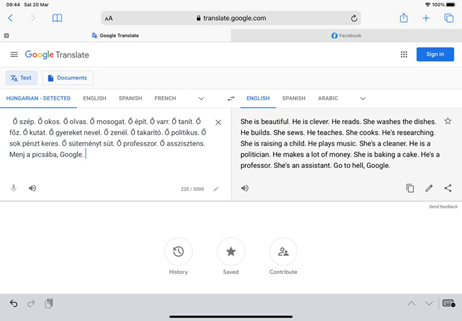
Oricine a folosit Google Translate în ultima perioadă, știe că uneltele de traducere online au ajuns la performanțe uluitoare în ultimii ani. Însă odată cu transferul datelor necesare (text, imagini, audio) pentru ca sistemele de inteligență artificială să ”învețe” să traducă atât de bine, oamenii au transferat și toate prejudecățile și stereotipurile de gen pe care le avem și care se reflectă uneori chiar și involuntar în conținutul pe care îl producem.
De exemplu, limba maghiară este neutră din perspectiva genului. Așa că Google Translate va alege automat un gen atunci când traduce din maghiară în engleză, atribuind roluri, activități și caracteristici diferite femeilor și bărbaților, în funcție de cum a fost învățat de datele pe care le-a primit de-a lungul timpului. Rezultatul arată ca în exemplul de mai sus, în care ea face toate activitățile casnice și este caracterizată prin atributele fizice, în timp ce el se ocupă de activități profesionale care necesită specializare intensivă și este mai degrabă caracterizat prin atributele cognitive. Pentru că de-a lungul timpului, imaginile care au fost folosite pentru a antrena sistemele de recunoaștere a imaginilor au amplificat stereotipurile – două colecții importante de imagini folosite în scopuri de cercetare, una susținută de Microsoft și una de Facebook, verificate într-un studiu, conțineau imagini cu cumpărături și activități de curățenie care erau atribuite femeilor, în timp ce activitățile sportive erau atribuite bărbaților. Fără să își dea seama, cei ce lucrau la antrenarea sistemelor de recunoaștere a imaginilor, le-au furnizat sistematic stereotipuri.
Sistemele care se bazează pe inteligență artificială învață pe măsură ce primesc seturi de date sub forma unor texte, imagini sau voce. De exemplu, dacă unui astfel de sistem îi vor fi arătate mai multe imagini cu cercetători bărbați și îi va fi descris ceea ce vede, acesta va învăța în timp să recunoască imagini similare. În timp, va învăța că cei mai mulți cercetători sunt bărbați. Dacă realitatea este că există mai mulți bărbați cercetători, e normal ca sistemul să învețe această informație, nu? Nu chiar. Problema e că astfel de sisteme nu doar că reflectă inegalitățile deja existente în realitate, ci le perpetuează și chiar le adâncesc.
De exemplu, un sistem de inteligență artificială care a învățat că cercetătorii sunt mai degrabă bărbați, odată integrat într-o platformă de recrutare, se va adresa cu precădere bărbaților. Așa că în continuare vor exista tot mai mulți bărbați care vor aplica la astfel de job-uri, din simplul motiv că le vor găsi mai ușor, perpetuând deci inegalitatea existentă acum. A existat o situație documentată în care platforma LinkedIn a furnizat sugestii de job-uri bine plătite cu precădere utilizatorilor bărbați, pentru că, din felul în care era folosită platforma, algoritmul din spatele ei înțelesese că acestea nu sunt căutate în aceeași măsură de femei.
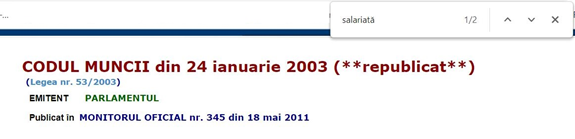
O altă situație ce poate crea deseori senzația că femeile sunt excluse din anumite categorii de activități este faptul că standardul masculin în exprimări este întâlnit în majoritatea conținutului produs. De exemplu, în Codul Muncii aplicabil în România, cuvântul ”salariată” apare în căutări doar de două ori – în contextul vârstei de pensionare, care este diferită pentru femei și bărbați, și în contextul imposibilității concedierii salariatei care este gravidă. În rest, în cele peste 250 de articole care alcătuiesc actul normativ, figurează standardul masculin al ”salariatului”.
Anul trecut, în Germania, a circulat ideea modificării Legii insolvenței în sensul folosirii exclusiv de termeni feminini – angajată în loc de angajat, sau chiriașă în loc de chiriaș. Ideea a fost contestată cu argumentul că o astfel de reglementare ar crea confuzie în rândul oamenilor, care ar putea crede că legea este aplicabilă doar femeilor. De cealaltă parte, modificările au fost susținute de cei ce cred că formulările care perpetuează standardul masculin exclud femeile sau creează senzația că ar fi mai puțin importante.
Poate părea un efort nenecesar, însă implicațiile etice ale sistemelor de inteligență artificială sunt un subiect de interes general la nivel global. Într-o lume în care tot mai multe decizii, precum cele de angajare sau de aprobare a unor credite, se vor face cu ajutorul acestor sisteme, este esențial să înțelegem felul în care ele sunt influențate de ceea ce le învățăm în prezent. Faptul că inegalitățile dintre femei și bărbați există în practică și că ele sunt transferate și acestor sisteme nu face decât să creeze un cerc vicios în care aceste diferențe să fie și mai bine consolidate.
Pentru rezolvarea problemei traducerilor încărcate de stereotipuri există ideea ”curățării” în prealabil a datelor pe care le furnizăm sistemelor de inteligență artificială de prejudecățile existente în ele și antrenarea sistemelor de la zero folosind conținut ”curățat”. Un astfel de proces ar dura însă foarte mult. Există și specialiști care au o idee mai punctuală – un fel de cursuri ”remediale” în care sistemele de inteligență artificială sunt învățate, de exemplu, cum să identifice fără prejudecăți anumite profesii unde în prealabil au fost identificate stereotipuri de gen în traduceri. Adică sistemele de inteligență artificiale sunt lăsate să fie antrenate complet cu conținutul deja existent și apoi sunt învățate să evite stereotipurile. Există un studiu care arată că adaptarea informațiilor deja procesate dă rezultate, cu o fracțiune din timpul necesar învățării de la zero.
Ceea ce am putea să facem noi între timp este să ne asigurăm că în conținutul pe care îl producem – de orice fel ar fi el: video, audio, articole, imagini -, în discuțiile pe care le avem cu cei din jur, sau în documentele pe care le redactăm, să nu perpetuăm aceleași stereotipuri care îngreunează învățarea sistemelor de inteligență artificială.
Dacă simțiți că există lucruri mult mai importante decât acest exercițiu al aplicării unei lentile feministe felului în care concepem conținut, amintiți-vă că în România suntem departe de a vorbi despre egalitate de gen. Suntem în continuare pe ultimele locuri printre statele membre ale Uniunii Europene când vine vorba despre politicile sociale care să asigure că femeile și bărbații au acces egal la piața muncii, resurse financiare, educație, putere decizională sau servicii de sănătate. Așa că orice pas mic în direcția asta, chiar și în domenii precum cele descrise mai sus, este unul necesar.
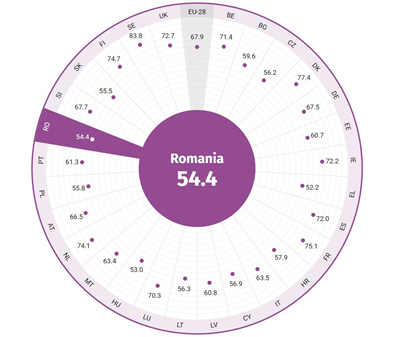
Cu 54,4 puncte din 100, România se află pe locul 26 între statele membre ale UE în ceea ce privește Indicele Egalității de Gen în 2020. Datele sunt colectate în 2018. Sursa: EIGE
Acest material a apărut prima dată în rubrica Starea Ideilor din newsletter-ul săptămânal Starea Nației.